Apache Spark 1.6 预览版:更简便的搜索
发布于 2015-12-21 10:52:20 | 294 次阅读 | 评论: 0 | 来源: 网友投递
Apache Spark
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
日前,Databricks公司发布了一个Apache Spark主要版本的可用性。除了可用性、可移植性等几个新的特性外,本次发布还提供了对尚未发布的Apache Spark 1.6预览。Databricks用户有机会在官方发布之前试用Spark 1.6的特性,包括在Databricks集成空间内轻松搜索Spark文档、点击几个按钮便能在不同Databricks实例间共享Databricks的notebooks。在本博文中,将对这些令人兴奋的新特性提供一个简短的介绍。
Apache Spark 1.6预览
Patrick Wendell宣布了Spark 1.6 预览版。我们很高兴该预览可用,以使我们的用户在快速发展的开源项目上能够占据优势。在Databricks公司网站上可以试用该Spark 1.6预览。
要从Databricks网站上获取该预览版,Databrick用户只需要通过Databricks集群管理器用户界面选择Version 1.6.0 (Preview),然后再运行该预览包即可。 创建Spark 1.6集群时可以同时保留更早版本的Spark集群,也可以将老版本的Spark应用程序代码运行在Spark 1.6集群当中以便测试1.6版的性能改进,目前的Databricks支持的Spark老版本包括1.3、1.4和1.5。由于Databricks支持运行多个Spark版本,用户在保证原有生产环境稳定的同时也能够试用新版本提供的新特性。
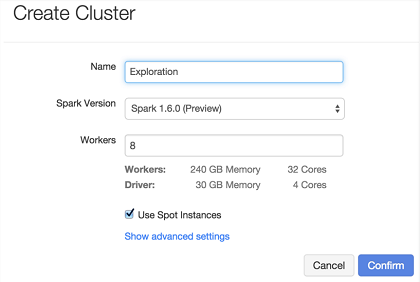
Patrick将在12月1日开展关于Spark 1.6的网络讲座,现在注册可以获取具体细节。
Databricks Notebooks可移植性的改进
之前,我们公布了一个新特性,该特性允许用户把notebooks导出为HTML格式。我们对该功能进行了扩展,扩展后支持将先前导出的HTML格式的notebook导入到任何Databricks实例中。这样的话用户在共享notebook和协作时具备更多的选择,包括跨越不同Databricks实例的协作。
更简易的Spark文档搜索
Databricks集成搜索特性为用户提供了更简便的查找相关信息的方式。通过该发布版,用户也可以轻松地在Spark官方文档中搜索,以查找最新的信息。

展望
作为一个SaaS平台,Databricks通过快速迭代持续不断地提升用户体验。如果你已经有Databricks账户,我们欢迎你尝试下这些新特征,并提供使用反馈意见。如果你有兴趣对Databricks先行试用一番,可以和我们任一个方案架构师联系,或者直接到官网注册试验。
原文链接:New Databricks release: Preview of Apache Spark 1.6, easier search, and more(译者/牛亚真 审校/朱正贵 责编/仲浩)
译者简介:牛亚真,中科院计算机信息处理专业硕士研究生,关注大数据技术和数据挖掘方向。
历史版本 :
Apache Spark 2.2.0 正式发布,提高可用性和稳定性
Spark 2.0 时代全面到来 —— 2.0.1 版本发布
Apache Spark 2.0.0 发布,APIs 更新
Apache Spark 1.6.2 发布,集群计算环境
Spark 2.0 预览:更简单,更快,更智能
Spark 2.7.6 发布,开源集群计算环境
Apache spark 1.6.1 发布,集群计算环境
Apache Spark 2.0 最快今年4月亮相
Apache Spark 1.6 正式发布,性能大幅度提升
Apache Spark 1.6 预览版:更简便的搜索
Apache Spark 1.5.2 发布,开源集群计算环境
Apache Spark 1.5.1 发布,开源集群计算环境