Java中ArrayList的removeAll方法详解
发布于 2018-01-05 10:58:17 | 233 次阅读 | 评论: 0 | 来源: 网友投递
Java程序设计语言
java 是一种可以撰写跨平台应用软件的面向对象的程序设计语言,是由Sun Microsystems公司于1995年5月推出的Java程序设计语言和Java平台(即JavaEE(j2ee), JavaME(j2me), JavaSE(j2se))的总称。
这篇文章主要给大家介绍了关于Java中ArrayList的removeAll方法的相关资料,文中通过示例代码介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面跟着小编一起来看看吧。
本文介绍的是关于Java中ArrayList的removeAll方法的相关内容,分享出来供大家参考学习,下面来一起看看详细的介绍:
在开发过程中,遇到一个情况,就是从所有骑手Id中过滤没有标签的骑手Id(直接查询没有标签的骑手不容易实现),
List<Integer> allRiderIdList = new ArrayList(); // 所有的骑手,大致有23W数据
List<Integer> hasAnyTagRiderId = new ArrayList(); // 有标签的骑手, 大致有21W数据
List<Integer> withoutAnyTagRiderList = allRiderIdList.removeAll(hasAnyTagRiderId);逻辑很简单,就是取一个差集,这样子就拿到没有任何标签的骑手数据。
但是在实际开发过程中,removeAll这个动作很耗时,做测试大概要4分钟左右。查看ArrayList中removeAll的源码片段:
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, false);
}
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++) // 循环原来的list
if (c.contains(elementData[r]) complement) // 这里调用contains方法
elementData[w++] = elementData[r];
} finally {
....
}
return modified;
}在循环过程中调用contains方法做比较,查一下ArrayList的contains方法,源代码片段如下:
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
if (o null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}这可以看出来,在比较的过程中,又调用了一次循环。
所以removeAll两层for循环,复杂度O(m*n),所以在操作比较大的ArrayList时,这种方法是绝对不可取的。
下面看一下最终的实现方式:
private List<Integer> removeAll(List<Integer> src, List<Integer> target) {
LinkedList<Integer> result = new LinkedList<>(src); //大集合用linkedlist
HashSet<Integer> targetHash = new HashSet<>(target); //小集合用hashset
Iterator<Integer> iter = result.iterator(); //采用Iterator迭代器进行数据的操作
while(iter.hasNext()){
if(targetHash.contains(iter.next())){
iter.remove();
}
}
return result;
}同样数量级list, 整个过程只需要几十毫秒,简直天壤之别。
回过头来,比较一下两种实现方式,为什么差距这个大。
1、外层循环
一个是普通的for循环,一个迭代器遍历元素,二者相差不大
2、内层数据比较
前者通过index方法把整个数组顺序遍历了一遍;
后者调用HashSet的contains方法,实际上是调用HashMap的containKey方法,查找时是通过hash表查找,复杂度为O(1)。
接下来我们简单看一下hash表。
hash表是一种特殊的数据结构,它同数组、链表以及二叉排序树等相比较有很明显的区别,它能够快速定位到想要查找的记录,而不是与表中存在的记录的关键字进行比较来进行查找。这个源于Hash表设计的特殊性,它采用了函数映射的思想将记录的存储位置与记录的关键字关联起来,从而能够很快速地进行查找。可以简单理解为,以空间换时间,牺牲空间复杂度来换取时间复杂度。
hash表采用一个映射函数 f : key —> address 将关键字映射到该记录在表中的存储位置,从而在想要查找该记录时,可以直接根据关键字和映射关系计算出该记录在表中的存储位置,通常情况下,这种映射关系称作为hash函数,而通过hash函数和关键字计算出来的存储位置(注意这里的存储位置只是表中的存储位置,并不是实际的物理地址)称作为hash地址。
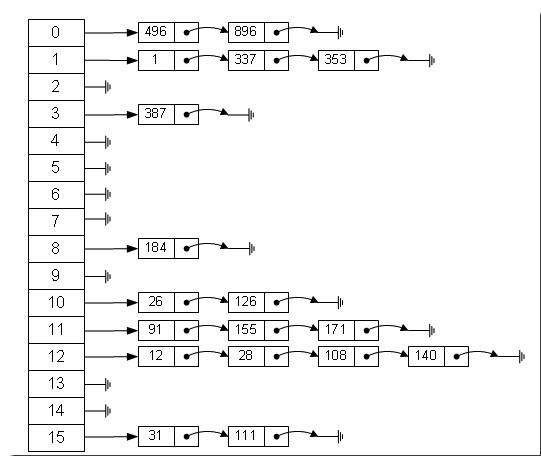
上面的图大家应该都很熟悉,hash表的一种实现方式,是由数组+链表组成的。元素放入hash表的位置通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。
另外hash表大小的确定也很关键,如果hash表的空间远远大于最后实际存储的记录个数,则造成了很大的空间浪费,如果选取小了的话,则容易造成冲突。在实际情况中,一般需要根据最终记录存储个数和关键字的分布特点来确定Hash表的大小。还有一种情况时可能事先不知道最终需要存储的记录个数,则需要动态维护Hash表的容量,此时可能需要重新计算Hash地址。
当然,关于hash表要说的话太多,先简单到此吧~~~
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对PHPERZ的支持。