python验证码识别的示例代码
发布于 2017-10-12 12:47:30 | 208 次阅读 | 评论: 0 | 来源: 网友投递
Python编程语言
Python 是一种面向对象、解释型计算机程序设计语言,由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年。Python语法简洁而清晰,具有丰富和强大的类库。它常被昵称为胶水语言,它能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。
本篇文章主要介绍了python验证码识别的示例代码,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧
写爬虫有一个绕不过去的问题就是验证码,现在验证码分类大概有4种:
- 图像类
- 滑动类
- 点击类
- 语音类
今天先来看看图像类,这类验证码大多是数字、字母的组合,国内也有使用汉字的。在这个基础上增加噪点、干扰线、变形、重叠、不同字体颜色等方法来增加识别难度。
相应的,验证码识别大体可以分为下面几个步骤:
- 灰度处理
- 增加对比度(可选)
- 二值化
- 降噪
- 倾斜校正分割字符
- 建立训练库
- 识别
由于是实验性质的,文中用到的验证码均为程序生成而不是批量下载真实的网站验证码,这样做的好处就是可以有大量的知道明确结果的数据集。
当需要真实环境下需要获取数据时,可以使用结合各个大码平台来建立数据集进行训练。
生成验证码这里我使用Claptcha这个库,当然Captcha这个库也是个不错的选择。
为了生成最简单的纯数字、无干扰的验证码,首先需要将claptcha.py的285行_drawLine做一些修改,我直接让这个函数返回None,然后开始生成验证码:
from claptcha import Claptcha
c = Claptcha("8069","/usr/share/fonts/truetype/freefont/FreeMono.ttf")
t,_ = c.write('1.png')这里需要注意ubuntu的字体路径,也可以在网上下载其他字体使用。生成验证码如下:
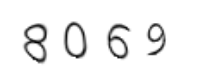
可以看出,验证码有形变。对于这类最简单的验证码,可以直接使用谷歌开源的tesserocr来识别。
首先安装:
apt-get install tesseract-ocr libtesseract-dev libleptonica-dev
pip install tesserocr然后开始识别:
from PIL import Image
import tesserocr
p1 = Image.open('1.png')
tesserocr.image_to_text(p1)
'8069\n\n'可以看出,对于这种简单的验证码,基本什么都不做识别率就已经很高了。有兴趣的小伙伴可以用更多的数据来测试,这里我就不展开了。
接下来,在验证码背景添加噪点来看看:
c = Claptcha("8069","/usr/share/fonts/truetype/freefont/FreeMono.ttf",noise=0.4)
t,_ = c.write('2.png')生成验证码如下:
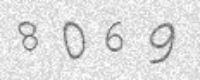
识别:
p2 = Image.open('2.png')
tesserocr.image_to_text(p2)
'8069\n\n'效果还可以。接下来生成一个字母数字组合的:
c2 = Claptcha("A4oO0zZ2","/usr/share/fonts/truetype/freefont/FreeMono.ttf")
t,_ = c2.write('3.png')生成验证码如下:
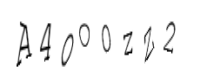
第3个为小写字母o,第4个为大写字母O,第5个为数字0,第6个为小写字母z,第7个为大写字母Z,最后一个是数字2。人眼已经跪了有木有!但现在一般验证码对大小写是不做严格区分的,看自动识别什么样吧:
p3 = Image.open('3.png')
tesserocr.image_to_text(p3)
'AMOOZW\n\n'人眼都跪的计算机当然也废了。但是,对于一些干扰小、形变不严重的,使用tesserocr还是十分简单方便的。然后将修改的claptcha.py的285行_drawLine还原,看添加干扰线的情况。
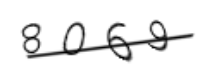
p4 = Image.open('4.png')
tesserocr.image_to_text(p4)加了条干扰线就完全识别不出来了,那么有没有什么办法去除干扰线呢?
虽然图片看上去是黑白的,但还需要进行灰度处理,否则使用load()函数得到的是某个像素点的RGB元组而不是单一值了。处理如下:
def binarizing(img,threshold):
"""传入image对象进行灰度、二值处理"""
img = img.convert("L") # 转灰度
pixdata = img.load()
w, h = img.size
# 遍历所有像素,大于阈值的为黑色
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
return img处理后的图片如下:
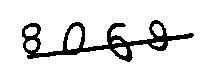
可以看出处理后图片锐化了很多,接下来尝试去除干扰线,常见的4邻域、8邻域算法。所谓的X邻域算法,可以参考手机九宫格输入法,按键5为要判断的像素点,4邻域就是判断上下左右,8邻域就是判断周围8个像素点。如果这4或8个点中255的个数大于某个阈值则判断这个点为噪音,阈值可以根据实际情况修改。
def depoint(img):
"""传入二值化后的图片进行降噪"""
pixdata = img.load()
w,h = img.size
for y in range(1,h-1):
for x in range(1,w-1):
count = 0
if pixdata[x,y-1] > 245:#上
count = count + 1
if pixdata[x,y+1] > 245:#下
count = count + 1
if pixdata[x-1,y] > 245:#左
count = count + 1
if pixdata[x+1,y] > 245:#右
count = count + 1
if pixdata[x-1,y-1] > 245:#左上
count = count + 1
if pixdata[x-1,y+1] > 245:#左下
count = count + 1
if pixdata[x+1,y-1] > 245:#右上
count = count + 1
if pixdata[x+1,y+1] > 245:#右下
count = count + 1
if count > 4:
pixdata[x,y] = 255
return img
处理后的图片如下:
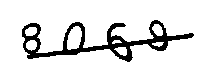
好像……根本没卵用啊?!确实是这样的,因为示例中的图片干扰线的宽度和数字是一样的。对于干扰线和数据像素不同的,比如Captcha生成的验证码:

从左到右依次是原图、二值化、去除干扰线的情况,总体降噪的效果还是比较明显的。另外降噪可以多次执行,比如我对上面的降噪后结果再进行依次降噪,可以得到下面的效果:
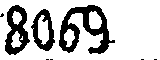
再进行识别得到了结果:
p7 = Image.open('7.png')
tesserocr.image_to_text(p7)
'8069 ,,\n\n'另外,从图片来看,实际数据颜色明显和噪点干扰线不同,根据这一点可以直接把噪点全部去除,这里就不展开说了。
第一篇文章,先记录如何将图片进行灰度处理、二值化、降噪,并结合tesserocr来识别简单的验证码,剩下的部分在下一篇文章中和大家一起分享。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持PHPERZ。