java实现简单的搜索引擎
发布于 2016-08-07 10:16:26 | 170 次阅读 | 评论: 0 | 来源: 网友投递
Java程序设计语言
java 是一种可以撰写跨平台应用软件的面向对象的程序设计语言,是由Sun Microsystems公司于1995年5月推出的Java程序设计语言和Java平台(即JavaEE(j2ee), JavaME(j2me), JavaSE(j2se))的总称。
这篇文章主要为大家详细介绍了java实现简单的搜索引擎的相关资料,需要的朋友可以参考下
记得java老师曾经说过百度的一个面试题目,大概意思是“有1W条无序的记录,如何从其中快速的查找到自己想要的记录”。这个就相当于一个简单的搜索引擎。最近在整理这一年的工作中,自己竟然已经把这个实现了,今天对其进一步的抽象,和大家分享下。
先写具体的实现代码,具体的实现思路和逻辑写在代码之后。
搜索时用于排序的Bean
/**
*@Description:
*/
package cn.lulei.search.engine.model;
public class SortBean {
private String id;
private int times;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public int getTimes() {
return times;
}
public void setTimes(int times) {
this.times = times;
}
}
构造的搜索数据结构以及简单的搜索算法
/**
*@Description:
*/
package cn.lulei.search.engine;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import cn.lulei.search.engine.model.SortBean;
public class SerachBase {
//details 存储搜素对象的详细信息,其中key作为区分Object的唯一标识
private HashMap<String, Object> details = new HashMap<String, Object>();
//对于参与搜索的关键词,这里采用的稀疏数组存储,也可以采用HashMap来存储,定义格式如下
//private static HashMap<Integer, HashSet<String>> keySearch = new HashMap<Integer, HashSet<String>>();
//HashMap中额key值相当于稀疏数组中的下标,value相当于稀疏数组在该位置的值
private final static int maxLength = Character.MAX_VALUE;
@SuppressWarnings("unchecked")
private HashSet<String>[] keySearch = new HashSet[maxLength];
/**
*@Description: 实现单例模式,采用Initialization on Demand Holder加载
*@Version:1.1.0
*/
private static class lazyLoadSerachBase {
private static final SerachBase serachBase = new SerachBase();
}
/**
* 这里把构造方法设置成私有为的是单例模式
*/
private SerachBase() {
}
/**
* @return
* @Description: 获取单例
*/
public static SerachBase getSerachBase() {
return lazyLoadSerachBase.serachBase;
}
/**
* @param id
* @return
* @Description: 根据id获取详细
*/
public Object getObject(String id) {
return details.get(id);
}
/**
* @param ids
* @return
* @Description: 根据ids获取详细,id之间用","隔开
*/
public List<Object> getObjects(String ids) {
if (ids == null || "".equals(ids)) {
return null;
}
List<Object> objs = new ArrayList<Object>();
String[] idArray = ids.split(",");
for (String id : idArray) {
objs.add(getObject(id));
}
return objs;
}
/**
* @param key
* @return
* @Description: 根据搜索词查找对应的id,id之间用","分割
*/
public String getIds(String key) {
if (key == null || "".equals(key)) {
return null;
}
//查找
//idTimes存储搜索词每个字符在id中是否出现
HashMap<String, Integer> idTimes = new HashMap<String, Integer>();
//ids存储出现搜索词中的字符的id
HashSet<String> ids = new HashSet<String>();
//从搜索库中去查找
for (int i = 0; i < key.length(); i++) {
int at = key.charAt(i);
//搜索词库中没有对应的字符,则进行下一个字符的匹配
if (keySearch[at] == null) {
continue;
}
for (Object obj : keySearch[at].toArray()) {
String id = (String) obj;
int times = 1;
if (ids.contains(id)) {
times += idTimes.get(id);
idTimes.put(id, times);
} else {
ids.add(id);
idTimes.put(id, times);
}
}
}
//使用数组排序
List<SortBean> sortBeans = new ArrayList<SortBean>();
for (String id : ids) {
SortBean sortBean = new SortBean();
sortBeans.add(sortBean);
sortBean.setId(id);
sortBean.setTimes(idTimes.get(id));
}
Collections.sort(sortBeans, new Comparator<SortBean>(){
public int compare(SortBean o1, SortBean o2){
return o2.getTimes() - o1.getTimes();
}
});
//构建返回字符串
StringBuffer sb = new StringBuffer();
for (SortBean sortBean : sortBeans) {
sb.append(sortBean.getId());
sb.append(",");
}
//释放资源
idTimes.clear();
idTimes = null;
ids.clear();
ids = null;
sortBeans.clear();
sortBeans = null;
//返回
return sb.toString();
}
/**
* @param id
* @param searchKey
* @param obj
* @Description: 添加搜索记录
*/
public void add(String id, String searchKey, Object obj) {
//参数有部分为空,不加载
if (id == null || searchKey == null || obj == null) {
return;
}
//保存对象
details.put(id, obj);
//保存搜索词
addSearchKey(id, searchKey);
}
/**
* @param id
* @param searchKey
* @Description: 将搜索词加入到搜索域中
*/
private void addSearchKey(String id, String searchKey) {
//参数有部分为空,不加载
//这里是私有方法,可以不做如下判断,但为了设计规范,还是加上
if (id == null || searchKey == null) {
return;
}
//下面采用的是字符分词,这里也可以使用现在成熟的其他分词器
for (int i = 0; i < searchKey.length(); i++) {
//at值相当于是数组的下标,id组成的HashSet相当于数组的值
int at = searchKey.charAt(i);
if (keySearch[at] == null) {
HashSet<String> value = new HashSet<String>();
keySearch[at] = value;
}
keySearch[at].add(id);
}
}
}
测试用例:
/**
*@Description:
*/
package cn.lulei.search.engine.test;
import java.util.List;
import cn.lulei.search.engine.SerachBase;
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
SerachBase serachBase = SerachBase.getSerachBase();
serachBase.add("1", "你好!", "你好!");
serachBase.add("2", "你好!我是张三。", "你好!我是张三。");
serachBase.add("3", "今天的天气挺好的。", "今天的天气挺好的。");
serachBase.add("4", "你是谁?", "你是谁?");
serachBase.add("5", "高数这门学科很难", "高数确实很难。");
serachBase.add("6", "测试", "上面的只是测试");
String ids = serachBase.getIds("你的高数");
System.out.println(ids);
List<Object> objs = serachBase.getObjects(ids);
if (objs != null) {
for (Object obj : objs) {
System.out.println((String) obj);
}
}
}
}
测试输出结果如下:
5,3,2,1,4,
高数确实很难。
今天的天气挺好的。
你好!我是张三。
你好!
你是谁?
这样一个简单的搜索引擎也就算是完成了。
问题一:这里面的分词采用的是字符分词,对汉语的处理还是挺不错的,但是对英文的处理就很弱。
改进方法:采用现在成熟的分词方法,比如IKAnalyzer、StandardAnalyzer等,这样修改,keySearch的数据结构就需要做下修改,可以修改为 private HashMap<String, String>[] keySearch = new HashMap[maxLength]; 其中key存储分的词元,value存储唯一标识id。
问题二:本文实现的搜索引擎对词元并没有像lucene设置权重,只是简单的判断词元是否在对象中出现。
改进方法:暂无。添加权重处理,使数据结构更加复杂,所以暂时没有对其做处理,在今后的文章中会实现权重的处理。
下面就简单的介绍一下搜索引擎的实现思路。
在SerachBase类中设置details和keySearch两个属性,details用于存储Object的详细信息,keySearch用于对搜索域做索引。details数据格式为HashMap,keySearch的数据格式为稀疏数组(也可以为HashMap,HashMap中额key值相当于稀疏数组中的下标,value相当于稀疏数组在该位置的值)。
对于details我就不做太多的介绍。
keySearch中数组下标(如用HashMap就是key)的计算方法是获取词元的第一个字符int值(因为本文的分词采用的是字符分词,所以一个字符就是一个词元),该int值就是数组的下标,相应的数组值就是Object的唯一标识。这样keySearch的数据结构就如下图
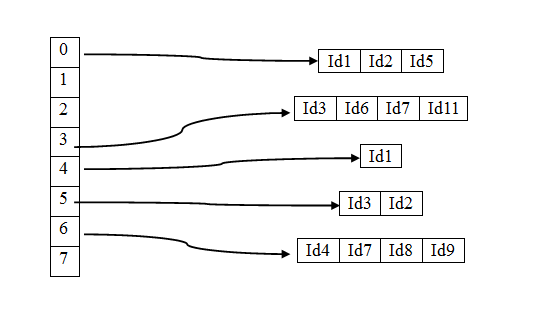
因此想添加新纪录的时候只需要调用add方法即可。
对于搜索的实现逻辑和上面的keySearch类似。对于id的搜索直接使用HashMap的get方法即可。对于搜索词的一个搜索,整体的过程也是采用先分词、其次查询、最后排序。当然这里面的分词要和创建采用的分词要一致(即创建的时候采用字符分词,查找的时候也采用字符分词)。
在getIds方法中,HashMap<String, Integer> idTimes = new HashMap<String, Integer>();idTimes 变量用来存储搜索词中的词元有多少个在keySearch中出现,key值为唯一标识id,value为出现的词元个数。HashSet<String> ids = new HashSet<String>(); ids变量用来存储出现的词元的ids。这样搜索的复杂度就是搜索词的词元个数n。获得包含词元的ids,构造SortBean数组,对其排序,排序规则是出现词元个数的降序排列。最后返回ids字符串,每个id用","分割。如要获取详细信息
再使用getObjects方法即可。
上述的只是一个简单的搜索引擎,并没有设计太多的计算方法,希望对大家的学习有所启发。