Druid Analytics 0.8.0 发布,OLAP 数据查询引擎
发布于 2015-07-21 09:56:25 | 264 次阅读 | 评论: 0 | 来源: 网友投递
Druid Java数据库连接池
Druid首先是一个数据库连接池 ,但它不仅仅是一个数据库连接池,它还包含一个ProxyDriver,一系列内置的JDBC组件库,一个SQL Parser。Druid是阿里巴巴开源平台上的一个项目,整个项目由数据库连接池、插件框架和SQL解析器组成。该项目主要是为了扩展JDBC的一些限制,可以让程序员实现一些特殊的需求,比如向密钥服务请求凭证、统计SQL信息、SQL性能收集、SQL注入检查、SQL翻译等,程序员可以通过定制来实现自己需要的功能。
Druid Analytics 0.8.0 发布,更新内容如下:
新特性
-
Redo Druid metrics to use an understandable metrics schema
-
Support compression for multi-value columns
-
Added longMax/longMin aggregators in addition to previous min/max [double] aggregators which have been renamed to appropriate doubleMax/doubleMin
-
Added a hadoop_convert_segment task for the indexer to allow large scale batch re-compression of old data as an indexer task.
改进
-
Index task now ignores invalid rows (#1264)
-
Improved segment filtering for dataSourceMetadataQuery (#1299)
-
Numerous additional unit tests
Bug 修复
-
Fixed deprecated warnings in Hadoop batch indexing (#1275). Thanks @infynyxx!
-
Fix groupBys applying limitSpecs to historicals on post aggregations (#1292). Thanks @guobingkun!
-
Fix incorrectly typed values in metadata sql queries (#1295). THanks @anubhgup!
-
Fix timeBoundary cache serde problems (#1303)
-
Fix serde issue with pulling timestamps from cache (#1304)
-
Fixed concatenated gzip files with static s3 firehose (#1311)
-
Fix audit table config serde problems (#1322)
-
Fix IRC firehose serde (#1331)
-
Fix Arithmetic exceptions on the broker (#1336)
-
Fix an error where the Convert Segment Task would leave zombie tasks if the task failed (#1363)
-
Fixed #1365 to return actual complex metric name in segment metadata query response
-
Fix groupBy caching to work with renamed aggregators (#1499)
文档
-
Numerous typo fixes. Thanks to @textractor, @rasahner, & @bobrik.
下载:https://github.com/druid-io/druid/archive/druid-0.8.0.zip。
Druid首先是一个数据库连接池 ,但它不仅仅是一个数据库连接池,它还包含一个ProxyDriver,一系列内置的JDBC组件库,一个SQL Parser。Druid是阿里巴巴开源平台上的一个项目,整个项目由数据库连接池、插件框架和SQL解析器组成。该项目主要是为了扩展JDBC的一些限制,可以让程序员实现一些特殊的需求,比如向密钥服务请求凭证、统计SQL信息、SQL性能收集、SQL注入检查、SQL翻译等,程序员可以通过定制来实现自己需要的功能。
Druid 是为大型数据集上实时探索查询的引擎,提供专为 OLAP 设计的开源分析数据存储系统,它的设计意图是在面对代码部署、机器故障以及其他产品系统遇到不测时能保持100%正常运行。它也可以用于后台用例,但设计决策明确定位线上服务。
数据流:
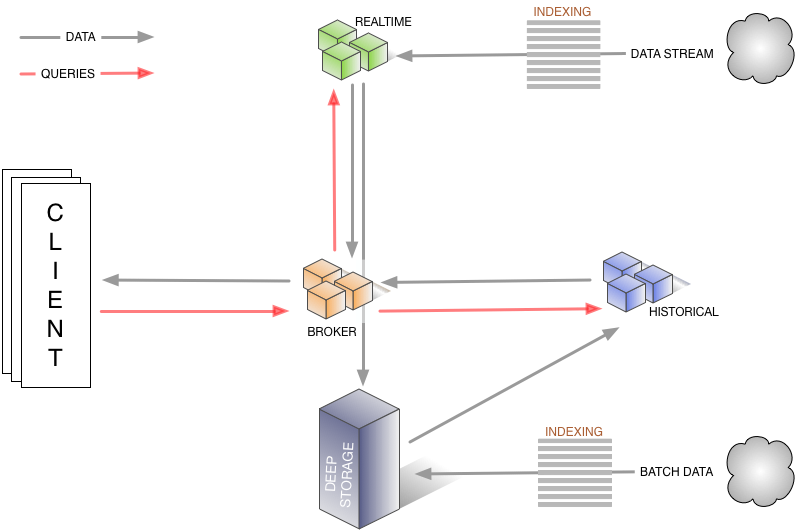
集群架构:
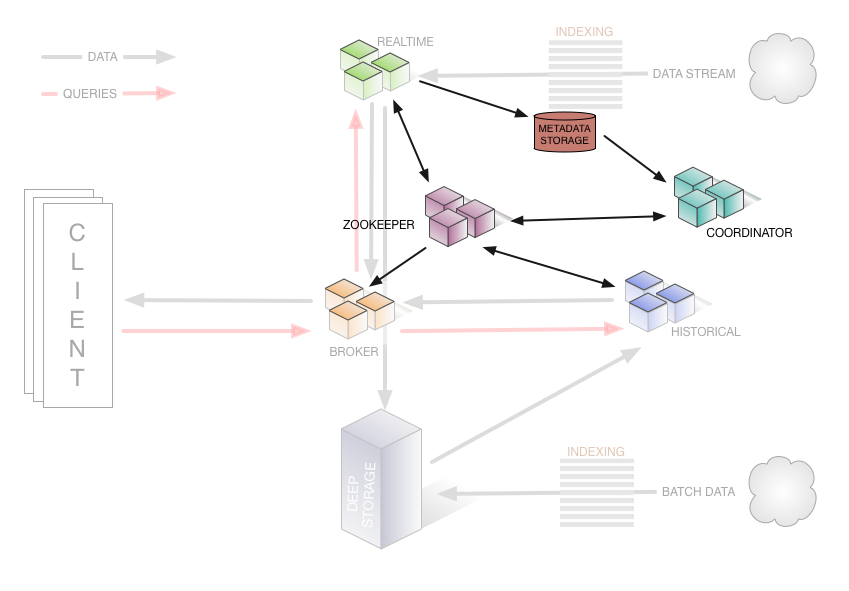
主要特性:
-
为分析而设计——Druid是为OLAP工作流的探索性分析而构建。它支持各种filter、aggregator和查询类型,并为添加新功能提供了一个框架。用户已经利用Druid的基础设施开发了高级K查询和直方图功能。
-
交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内查询,因为Druid的查询延时通过只读取和扫描优必要的元素被优化。Aggregate和 filter没有坐等结果。
-
高可用性——Druid是用来支持需要一直在线的SaaS的实现。你的数据在系统更新时依然可用、可查询。规模的扩大和缩小不会造成数据丢失。
-
可伸缩——现有的Druid部署每天处理数十亿事件和TB级数据。Druid被设计成PB级别。
历史版本 :
Druid 1.1.4 发布,阿里开源连接池
Druid 1.1.2 发布,阿里开源连接池
阿里开源连接池 Druid 发布 1.1.1 版本
druid-1.1.0 发布,提供 spring-boot-starter
Druid 1.0.29 发布,阿里数据库连接池
Druid 1.0.28 发布,阿里数据库连接池
处理大数据的分布式系统 Druid-IO 发布 0.9.2
Druid 1.0.27 发布,Bug 修复和功能增强
Druid-1.0.26 发布,增强语法解析支持
Druid 1.0.24 发布,增强语法解析支持
Druid-1.0.23 发布,增强 SQL 语法解析
Druid-1.0.22 发布,增强SQL语法解析