linux下配置部署Hadoop和Hbase
发布于 2014-10-18 06:19:10 | 335 次阅读 | 评论: 1 | 来源: 网友投递
Hadoop分布式系统
一个分布式系统基础架构,由Apache基金会所开发。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。
Hadoop是一个分布式系统基础架构,由Apache基金会所开发。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
1.环境准备
1.1准备安装介质
Hadoop官网下载地址:
http://www.apache.org/dyn/closer.cgi/hadoop/common/
Hive官网下载地址:
http://www.apache.org/dyn/closer.cgi/hive/
HBase官网下载地址:
http://www.apache.org/dyn/closer.cgi/hbase/
1.2卸载open-java
查看系统自带的已经安装的java
$rpm -qa | grep java
java-1.4.2-gcj-compat-1.4.2.0-40jpp.115
java-1.6.0-openjdk-1.6.0.0-1.7.b09.el5
卸载自带java
$rpm -e --nodeps java-1.4.2-gcj-compat-1.4.2.0-40jpp.115
$rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.7.b09.el5
1.3安装Sun-jdk
$cd /usr
unzip Sun-JDK
$vim /etc/profile
export JAVA_HOME=/usr/jdk1.6
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
$source /etc/profile
1.4编辑hosts文件
将集群中所有服务器的hostname添加到hosts文件中
$vi /etc/hosts
1.5关闭selinux安全验证和iptables
1.5.1关闭selinux安全验证
$vi /etc/sysconfig/selinux
修改SELINUX变量为disabled
SELINUX=disabled
使设置生效,不用重启机器
$setenforce 0
1.5.2关闭iptables
停止服务
$service iptables stop
关闭开机启动
$chkconfig iptables off
1.6创建新用户
1.6.1创建用户修改密码
$useradd hd
$passwd hd
1.6.2集群间设置ssh无密码访问
$mkdir ~/.ssh
$chmod 700 ~/.ssh/
在集群中所有服务器上生成密钥文件
$ cd ~/.ssh
$ ssh-keygen -t dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
$ chmod 600 ~/.ssh/authorized_keys
合并所有的authorized_keys文件,并同步到所有服务器节点上。
2.安装Hadoop
2.1解压 Hadoop tar包
$tar -xzf hadoop-1.1.0.tar.gz
2.2设置Hadoop环境变量
$vi /etc/profile
增加以下环境变量
export HADOOP_HOME=/home/hd/hadoop/hadoop-1.1.0
export PATH=$PATH:$HADOOP_HOME/bin
生效修改
$source /etc/profile
2.3修改Hadoop的配置文件
2.3.1配置conf/core-site.xml文件
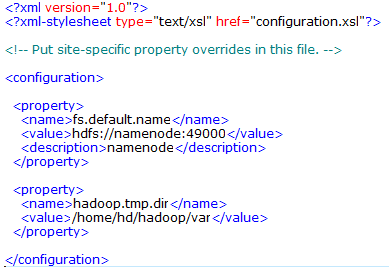
-
fs.default.name是NameNode的URI。hdfs://主机名:端口/
-
hadoop.tmp.dir:Hadoop的默认临时路径,这个最好配置,如果在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。不过如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式化的命令。
2.3.2配置conf/mapred-site.xml文件
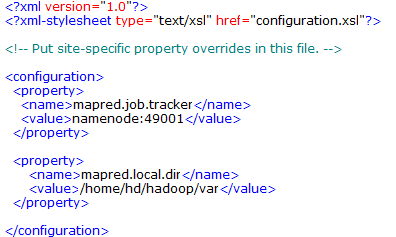
2.3.3配置conf/ hdfs-site.xml文件
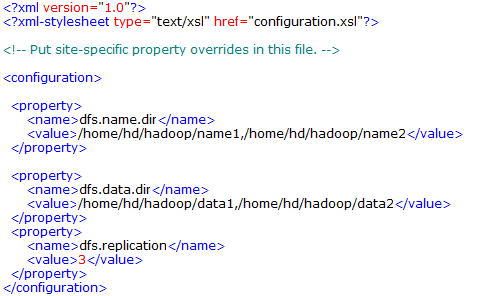
-
dfs.name.dir是NameNode持久存储名字空间及事务日志的本地文件系统路径。
当这个值是一个逗号分割的目录列表时,nametable数据将会被复制到所有目录中做冗余备份。 -
dfs.data.dir是DataNode存放块数据的本地文件系统路径,逗号分割的列表。
当这个值是逗号分割的目录列表时,数据将被存储在所有目录下,不用于Namenode的冗余机制,Datanode将轮询地存储数据,所以讲Datanode的不同路径分布在不同的物理硬盘上将提升性能。 -
dfs.replication是数据需要备份的数量,默认是3,如果此数大于集群的机器数会出错。
-
name1、name2、data1、data2目录不能预先创建,hadoop格式化时会自动创建。
2.3.4配置conf/hadoop-env.sh文件
增加JAVA_HOME环境变量
export JAVA_HOME=/usr/jdk1.6
2.3.5配置masters文件
配置SecondaryNameNode,也可以配置成自己
$vi masters
manmenode
其中namenode是master服务器主机名
2.3.6配置slaves文件
$vi slaves

其中node1-8为datanode服务器主机名
2.4启动Hadoop
2.4.1格式化NameNode
$./bin/hadoop namenode –format
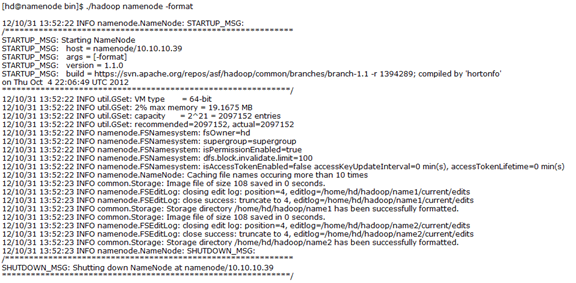
格式化成功后在hdfs-site.xml中配置的/home/hd/hadoop/name1和/home/hd/hadoop/name2两个目录会自动生成。
2.4.2启动Hadoop
$./bin/start-all.sh

启动成功后在hdfs-site.xml中配置的/home/hd/hadoop/data1和/home/hd/hadoop/data2两个目录会自动生成。
2.4.3查看WEB页面
NameNode - http://master:50070/
JobTracker - http://master:50030/
3安装HBase
3.1解压HBase tar包
$tar –xvf hbase-0.94.1.tar.gz
3.2设置Hbase的环境变量
$vi /etc/profile
增加以下环境变量
export HBASE_HOME=/home/hd/hbase/hbase-0.94.1
export PATH=$PATH:$HBASE_HOME/bin
生效修改
$source /etc/profile
3.3修改HBase的配置文件
3.3.1配置conf/hbase-site.xml文件

-
hbase.rootdir是Hbase的根目录位置url地址需要跟Hadoop设置的一致。该项不识别机器IP,只能使用hostname
-
hbase.cluster.distributed是是否采用分布式模式。
-
hbase.zookeeper.quorum是运行Zookeeper节点的主机名,个数必须为奇数。
3.3.2配置hbase-env.sh文件
export JAVA_HOME=/usr/jdk1.6
export HBASE_MANAGES_ZK=true
-
HBASE_MANAGES_ZK是设置是否让Hbase管理Zookeeper
3.3.3配置regionservers文件

3.4启动Hbase
$./bin/stat-hbase.sh
3.5查看WEB页面
HBase Master - http://master:60010/